腾讯发布SRPO算法,提升文生图模型真实感
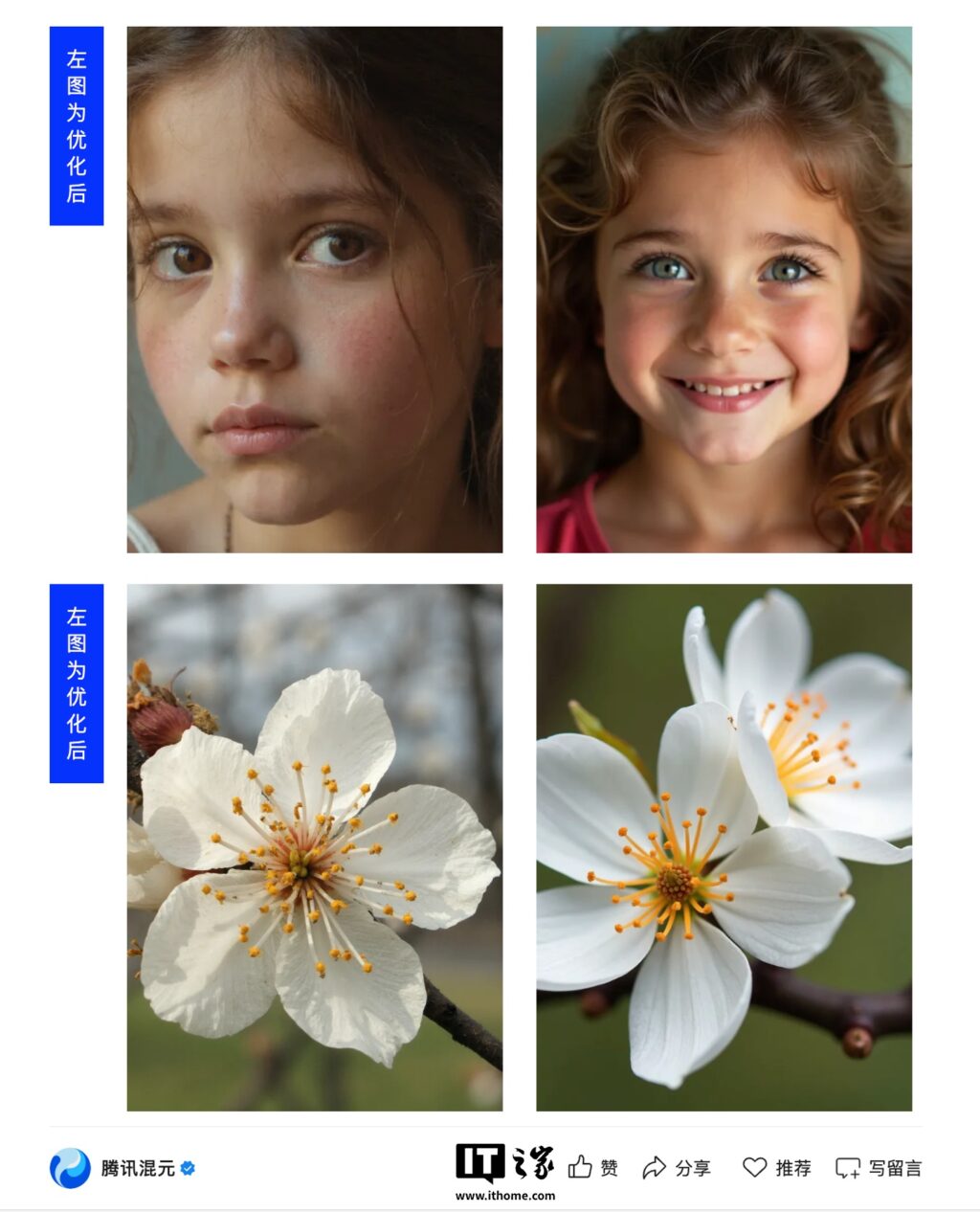
9月17日消息,腾讯混元团队在官方公众号上宣布了一项新的研究成果:SRPO算法。该算法旨在解决开源文生图模型Flux的皮肤质感“过油”问题,使人像的真实感提升三倍。此消息一经发布,便迅速登上了Hugging Face热度榜的榜首,社区量化版本下载量达到25,000次,GitHub上的Star数超过700个。
Flux作为开源文生图社区中最广泛使用的基础模型,其生成的人物质感问题一直是用户关注的焦点。针对这一问题,SRPO(Semantic Relative Preference Optimization,语义相对偏好优化)提供了创新的解决方案,包括在线调整奖励偏好和优化早期生成轨迹。
技术创新与合作背景
此次研究由腾讯混元团队与香港中文大学(深圳)及清华大学联合开展,提出了语义相对偏好优化这一创新性方法。SRPO通过为奖励模型添加特定的控制提示词(如“真实感”),以定向调整其优化目标。
“实验结果显示,这些控制词可以显著增强奖励模型在真实度等特定维度的优化能力。”
然而,研究人员也发现,单纯的语义引导仍存在奖励破解的风险。为此,团队提出了“语义相对偏好优化”策略:同时使用正向词和负向词作为引导信号,通过负向梯度有效中和奖励模型的一般性偏差,同时保留语义差异中的特定偏好。
解决过拟合问题的新策略
传统方法如ReFL和DRaFT通常仅优化生成轨迹的后半段,容易导致奖励模型在高频信息上的过拟合问题。具体表现为:HPSv2奖励模型偏好偏红色调的图像,PickScore倾向于紫色图像,而ImageReward则容易对过曝区域给出较高评分。
基于这些发现,研究团队提出了Direct-Align策略,对输入图像进行可控的噪声注入,随后通过单步推理,借助预先注入的噪声作为“参考锚点”进行图像重建。这种方法显著降低了重建误差,实现更精准的奖励信号传导,从而支持对生成轨迹的前半段进行优化,解决过拟合问题。
SRPO的高效性与未来展望
SRPO不仅在技术上取得了突破,其训练效率也极高。仅需10分钟训练即可全面超越DanceGRPO的效果。SRPO的定量指标达到SOTA水平,人类评估的真实度和美学优秀率提升超过三倍,训练时间相比DanceGRPO降低了75倍。
“SRPO的推出标志着文生图模型在真实感和效率上的新里程碑。”
随着SRPO的发布,文生图领域的研究将迎来新的发展机遇。其高效的训练方法和显著的效果提升,或将引领未来文生图模型的优化方向。研究团队表示,将继续探索更多创新的算法,以推动该领域的技术进步。



