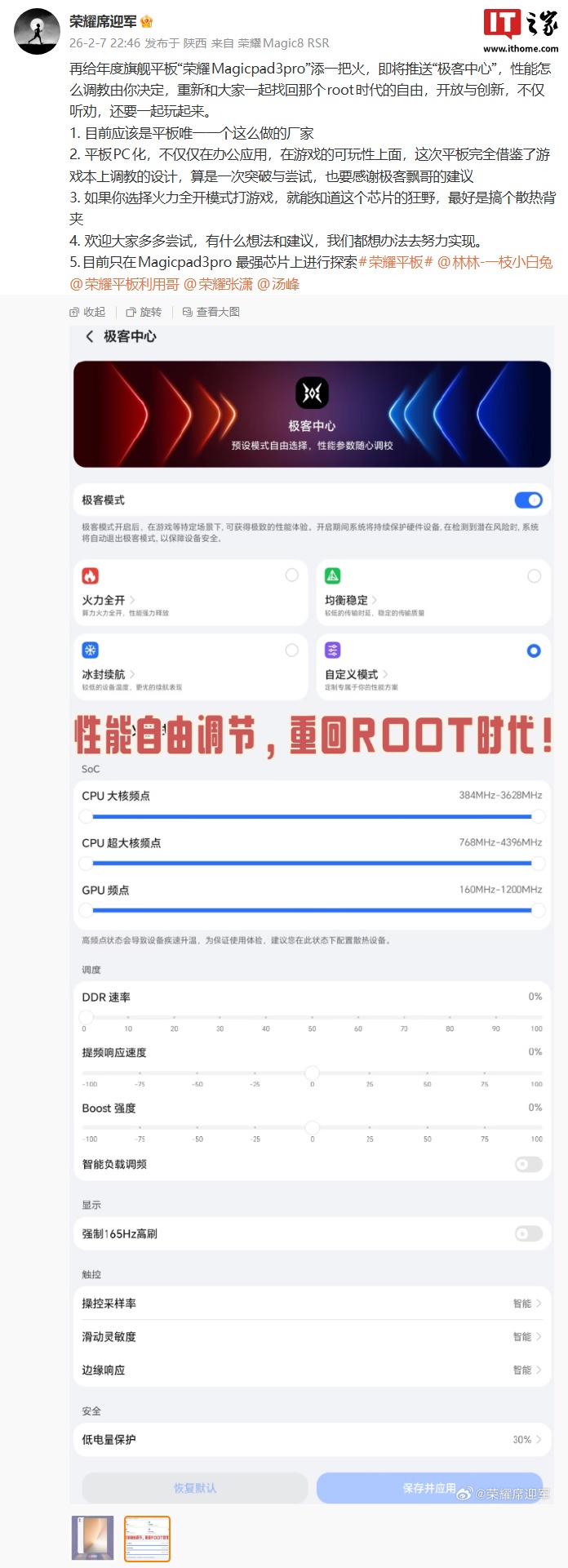
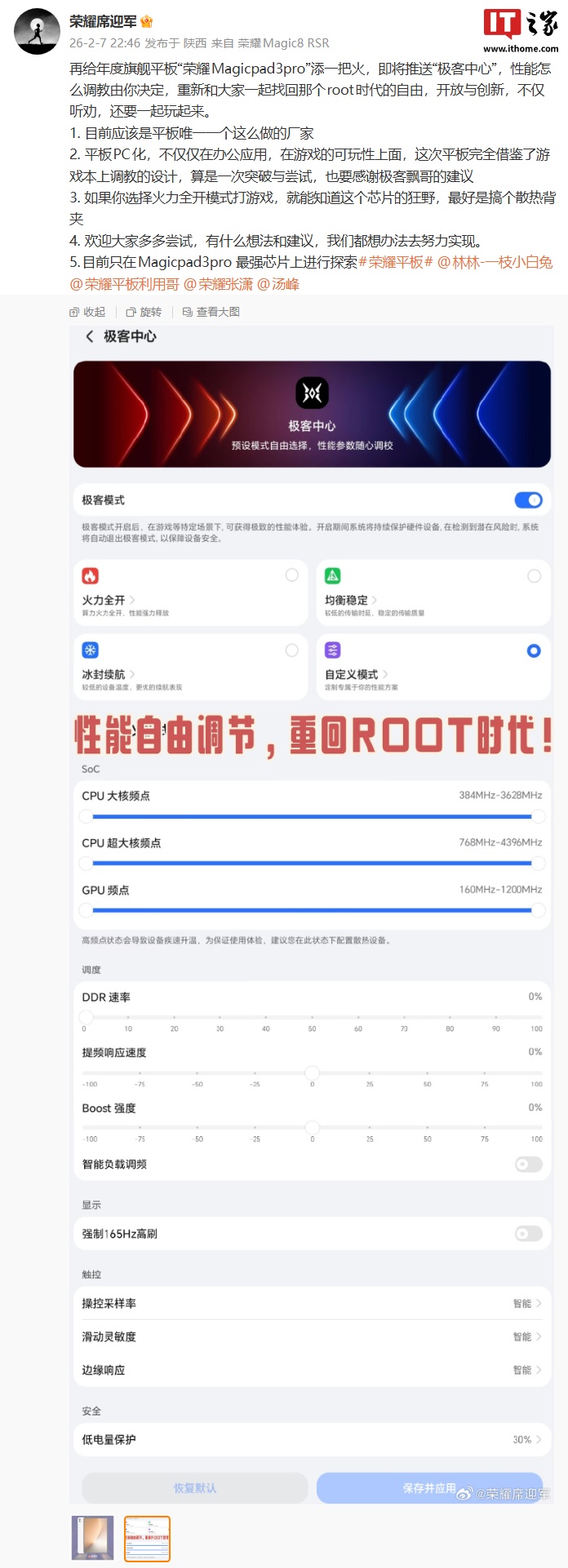
上海发布全球首个万亿参数科学大模型,推动AI科学革命

科学智能领域迎来了一次里程碑式的“上海时刻”。2月4日晚,上海人工智能实验室宣布,开源全球首个基于“通专融合”架构的万亿参数科学多模态大模型——Intern(书生)-S1-Pro。这一模型不仅是全球开源社区中参数规模最大的科学模型,其性能也稳居全球第一梯队,标志着科学智能从“工具革命”的1.0时代跨入由“革命性工具”驱动科学发现的2.0时代。
在人工智能领域,模型的参数规模往往决定了其“脑容量”。此次发布的书生科学模型,参数量达到惊人的1万亿(1T),刷新了行业纪录。然而,这一巨大的参数规模并未使模型变得笨重。
创新架构与突破性技术
书生万亿科学大模型采用了创新的混合专家架构(MoE)。形象地说,其内部相当于有512位各领域“顶尖专家”坐镇,系统会精准调用最合适的8位“专家”参与分析决策。这种“按需点将”机制,使模型只需激活约2%的参数(220亿),即可从容应对复杂数理逻辑推理。
更精妙的是,书生模型通过底层创新,实现了“物理直觉”的跨越。相较于语言处理,AI模型在解决科学问题时面临许多新挑战。为此,上海人工智能实验室引入“傅里叶位置编码(FoPE)”并重构“时序编码器”,赋予模型“双重听觉”与“双重视觉”,既能感知微观细节,也能宏观把握全局。
跨学科能力与应用前景
书生万亿科学大模型在实战中初步显现出过人实力。在国际数学奥林匹克(IMO-Answer-Bench)和国际物理奥林匹克(IPhO2025)等权威基准测试中,展现了竞赛级别的解题能力。在科学智能的其他关键垂直领域,表现同样出色。
“书生万亿科学大模型成功构建了一个横跨化学、材料、生命、地球、物理等五大核心学科的全谱系能力矩阵,涵盖100多个专业子任务。”
未来,随着理解与推理能力的增强,该模型的“能力边界”将进一步向真实科研场景延伸。其应用范围将从化学逆合成、蛋白质序列生成,拓展到遥感图像分析等复杂任务。
国产生态的深度融入
大模型的应用成效受制于算力、算法、数据等多维度因素。书生万亿大模型不仅在算法层面取得突破,更在算力层面实现了国产自主技术的全链路集成。
上海人工智能实验室通过“路由稠密估计”“分组路由”等策略,像智能交通系统一样对计算芯片负载进行均衡,攻克了超大规模模型训练的核心瓶颈。值得一提的是,在模型架构设计之初,实验室与昇腾计算生态确立了联合研发路线,实现了从算子优化到训练框架的深度适配。
“目前,书生系列大模型及全链路开发工具的开源体系,已吸引全球数十万开发者参与。”
下一步,上海人工智能实验室将持续推动全链条开源与免费商用,进一步降低全球科研门槛,与全球学术界和产业界一道,打造一个更开放、高效且面向未来的科学人工智能生态。