阶跃星辰发布 Step-Audio 2 mini 语音模型,性能超越同类产品
IT之家 9 月 1 日消息,阶跃星辰今日正式发布了开源端到端语音大模型 Step-Audio 2 mini。这一最新模型在多个国际基准测试集上取得了 SOTA(State Of The Art)成绩,标志着语音技术领域的又一重大突破。Step-Audio 2 mini 现已上线阶跃星辰开放平台,供开发者和研究人员使用。
据官方介绍,Step-Audio 2 mini 通过统一建模实现了语音理解、音频推理与生成的整合,并率先支持语音原生的 Tool Calling 能力,这使得模型可以执行联网搜索等复杂操作。
性能卓越,超越同类模型
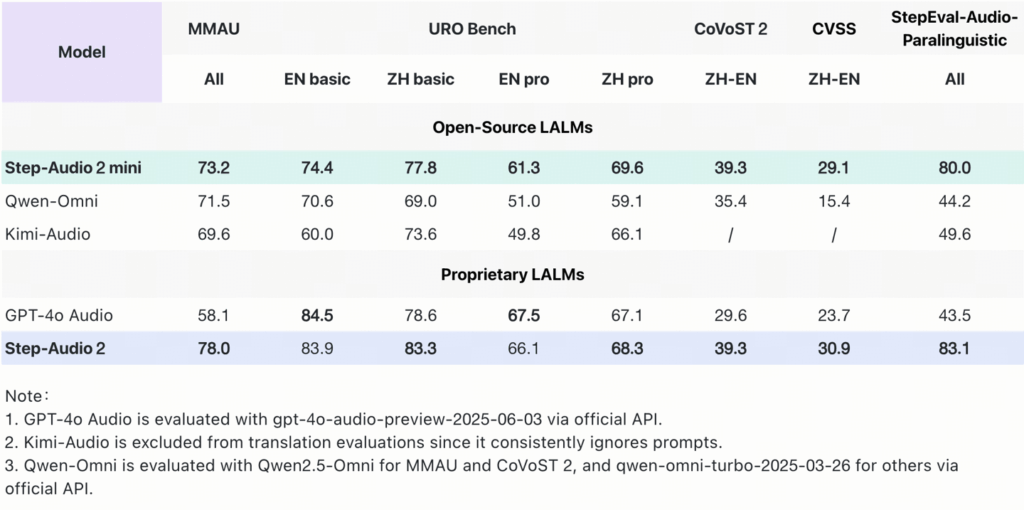
Step-Audio 2 mini 在多个关键基准测试中表现突出,尤其是在音频理解、语音识别、翻译和对话场景中,其综合性能超越了 Qwen-Omni、Kimi-Audio 等所有开源端到端语音模型,并在大部分任务上超越了 GPT-4o Audio。
“Step-Audio 2 mini 的发布标志着语音技术的又一次飞跃,其在多个测试中取得的 SOTA 成绩证明了其卓越的性能和广泛的应用潜力。”
解决语音模型的传统问题
长期以来,AI 语音技术常被批评为“智商、情商双低”。一方面是“没知识”,缺乏像文本大模型一样的知识储备和推理能力;另一方面是“冷冰冰”,难以理解潜台词、语气、情绪等“弦外之音”。
Step-Audio 2 mini 通过创新架构设计,有效解决了这些问题。其综合性能的提升不仅体现在技术指标上,也在实际应用中展现出更为人性化的交互体验。
技术背景与未来展望
阶跃星辰的这一发布正值全球对语音技术需求不断增长之际。随着智能设备的普及和语音交互的日益重要,语音模型的性能和应用场景成为行业关注的焦点。
业内专家指出,Step-Audio 2 mini 的推出不仅是技术上的突破,也为未来的语音交互应用奠定了基础。其在多语言支持、实时翻译和情感识别等领域的潜力将进一步推动语音技术的发展。
“未来,随着技术的不断进步,语音模型将更加智能化和人性化,为用户提供更自然的交互体验。”
目前,Step-Audio 2 mini 已在 GitHub、Hugging Face 和 ModelScope 等平台上线,开发者和研究人员可以通过这些平台获取和使用该模型。
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。






